
I’ve recently started in the world of Kubernetes (or K8s as you cool kids call it), and for the most part, I’ve been able to map MOST of the concepts of Instance based deployments in AWS, to Kubernetes configurations in AKS/Azure. However, we hit an issue when it came to credentials.
The Problem
When we started looking at this, we had the following requirements.
1. Store and read secure information like UserIds and Passwords that pods needed.
and
2. Cycle/Rotate these credentials periodically.
The second part is probably the most important here as it brings in the idea of how an immutable artifact like a pod can be cycled effectively, and how third party/managed services handle cycling of credentials.
What we tried
- ConfigMap created via Helm at Deploy time
Everything ends up in a place that is readable by everyone who can access the cluster, un-encrypted. - K8s Secrets – Not really any better than ConfigMaps are they’re just Base 64 encoded
- Azure KeyVault – Great, but you still need to store the credential information for KeyVault in one of the above.
Finally, we found PodIdentity, which is a new project from The Azure team (https://github.com/Azure/aad-pod-identity).
What is PodIdentity
From an Azure person’s standpoint, you can think of this as applying a ServicePrincipal to a Pod, in the same way as you would apply it to VM, an AppService, or a Function.
From an AWS person’s perspective, you can think of this as applying the equivalent of IAM roles to pods.
PodIdentity at it’s core, creates a “metadata” endpoint within each selected pod, that allows you to retrieve a security token for the identity. e.g.
http://169.254.169.254/metadata/identity/oauth2/token?api-version=2018-02-01&resource=https://vault.azure.net
The reason this is so key is that this is the same location that you would use for a VM, AppService, etc. Therefore, all tooling that works in those environments, will now work in the pod, so your code is portable through all Azure based deployments without fundamentally changing the code.
How does it work
I’m not a Kubernetes, or Azure expert, so all I have is my lazy mental model that hopefully will allow you to reason about this better.
PodIdentity as a concept is a “Broker” between your Pod and Azure AD’s ServicePrincipals.
Here’s a quick diagram with a few of the Parts.
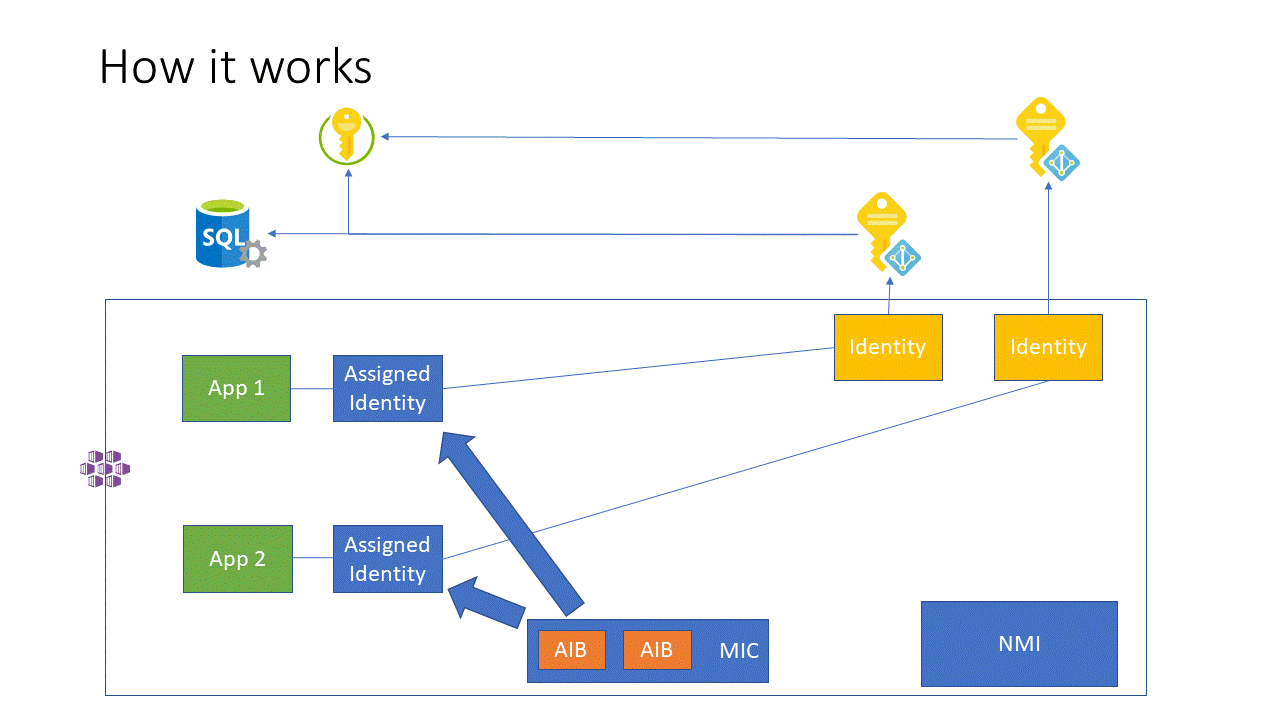
Standard Components
There are some standard resources that you have to import to your cluster (which in my opinion should be a simple checkbox, or cli switch, in Azure). These are the “infrastructure part” and act as the broker components to interact with Azure and the Kubernetes APIs to apply the identities. These are the NMI (DaemonSet), and the MIC (Pods).
NMI
This is the things that brokers access to the Azure, through the Cluster nodes.
MIC
This is what “Assigns” identities to pods by monitoring Kubernetes to see when a pod is created.
ServicePrincipal/Identity Mapping Resources
AzureIdentity
This is a Kubernetes resource that maps to a single Azure Identity, and is the resource pods will use to link to the external identity. You create this as a resource in your cluster, with at least 1 per identity you want to use.
AzureIdentityBinding
This is a Kubernetes resource that provides the configuration of how pods are found and linked to the AzureIdentity. You create this as a resource in your cluster with at least 1 per AzureIdentity you’ve created (you can have multiple).
AzureAssignedIdentities
This is the ultimate map between your pod and the AzureIdentity. This is created by the 2 previous components automatically, and destroyed automatically too.
The Process
The whole process works by the MIC watching for Pods being created (using the Kubernetes APIs) and then checking to see if there is “Binding” that should be applied to the Pod.
If the MIC finds that the labels on your pod match an AzureIdentityBinding resource, it will then create a AzureAssignedIdentities resource that maps an AzureIdentity. Then it will also adjust the pod’s networking so that the metadata endpoint is setup and routed properly.
From here, it’s all about the core components proxying and caching the identities and requests for them.
Conclusion
PodIdentity is definitely the way to go with working with Azure resources inside Kubernetes. It’s building on top of the foundation of other work, and not reinventing new libraries and concepts, which is great.
There’s some concepts in there that could maybe be done a little different, but largely, it’s things that you set once as part of the infrastructure then forget about it.
In Part 2, we’ll work through setting it up.

Leave a comment